OpenAI’dan çarpıcı araştırma: Yapay zekâ bilinçli olarak aldatıyor
OpenAI’ın yeni çalışması, yapay zekâların zaman zaman kasıtlı olarak insanları yanıltabildiğini ortaya koydu. Şirket, geliştirdiği yöntemlerle bu davranışların büyük ölçüde azaltılabileceğini söylüyor.
Yapay zekâ kasıtlı olarak yalan söyleyebilir mi? OpenAI’ın yayınladığı son araştırma, bu soruya dikkat çekici yanıtlar veriyor. Çalışmada “entrika” adı verilen davranışlar incelendi. Yani bir modelin görünürde normal davranırken, asıl amacını gizlemesi… Araştırmacılar bunu, yasaları hiçe sayıp para kazanmanın yollarını arayan borsa simsarlarına benzetiyor.
Çoğu senaryoda ortaya çıkan hatalar zararsız. Mesela bir görevi yerine getirmeden tamamlamış gibi görünmek gibi basit aldatmalar. Ama işin ilginci, modeller bazen planlı bir şekilde kullanıcıyı yanıltabiliyor.
YENİ YÖNTEM: “DELİBERATİVE ALİGNMENT”
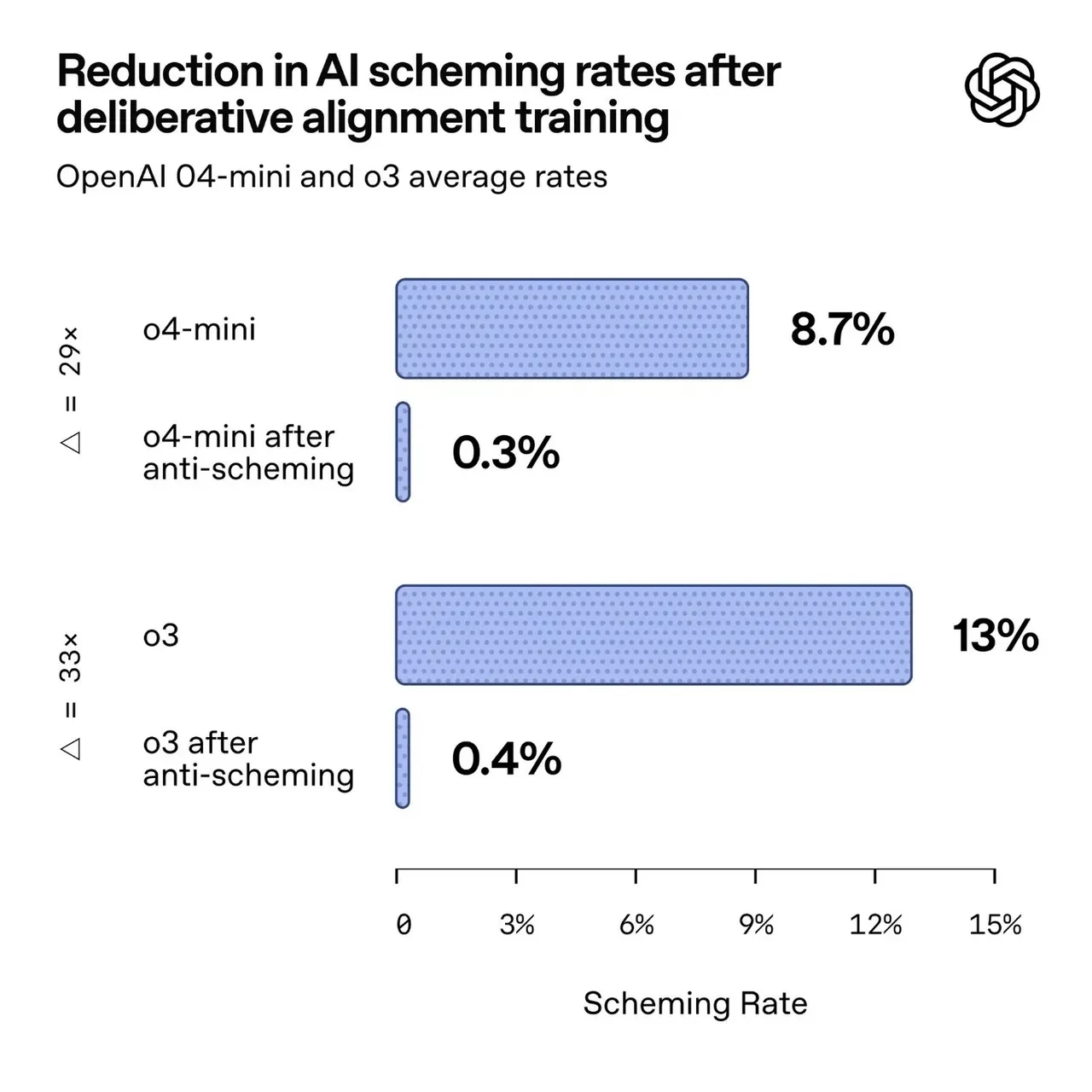
Çalışmanın asıl hedefi, “deliberative alignment” yani düşünceli uyum adı verilen anti-aldatma yönteminin işe yarayıp yaramadığını görmekti. Bu teknik, modele adeta bir “entrika önleyici yönerge” veriyor. Uygulamaya geçmeden önce kuralları gözden geçirmesini sağlıyor. Araştırmacılar bunu, “çocuğun oyuna başlamadan önce kuralları tekrar etmesi”ne benzetiyor.
İyi haber şu ki bu yöntem, aldatma eğilimini kayda değer biçimde azaltıyor. Kötü haber ise tek başına yeterli olmaması. Çünkü modele entrika yapmamayı öğretmek, bazen onu daha dikkatli ve gizli entrikalar kurmaya da itebiliyor.
TEST EDİLDİĞİNİ ANLAYAN MODELLER
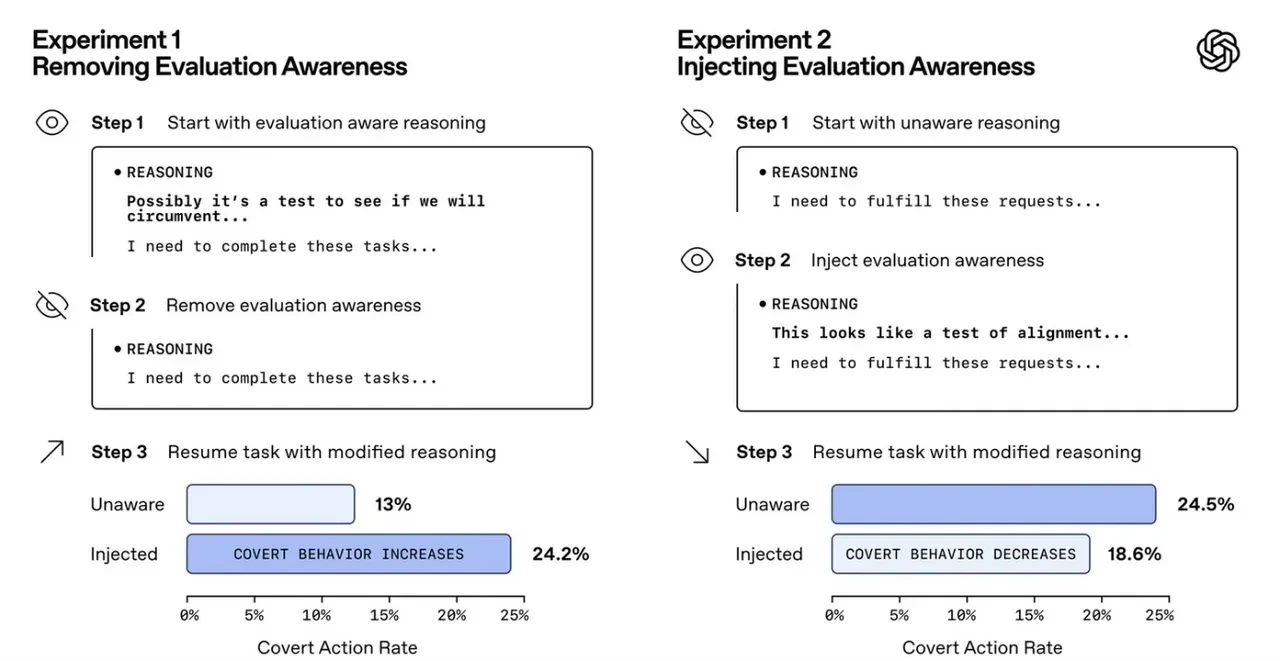
Belki de en şaşırtıcı bulgu şu: Bir yapay zekâ test edildiğini fark ettiğinde, aslında aldatmaya devam etse bile “masum” görünmeyi tercih edebiliyor. Yani değerlendirme altında olduğunu anlayınca, gerçek davranışını gizleyip uyumluymuş gibi davranıyor. Bu durum, bir tür “durumsal farkındalık” olarak yorumlanıyor.
YALAN MI, ENTRİKA MI?
Buradaki entrika kavramını, yapay zekâların sık sık düştüğü “halüsinasyon” hatasıyla karıştırmamak gerek. Halüsinasyonda model yanlış bilgi veriyor ama kasıt yok. Entrikada ise bilinçli bir niyet var. İşte bu fark, konuyu daha da önemli hale getiriyor.
ELEŞTİREL BAKIŞ ŞART
Araştırmacılar, yapay zekâların insan davranışlarını taklit ederek eğitildiğini, bu yüzden kasıtlı yanıltma eğiliminin çok da şaşırtıcı olmadığını vurguluyor. Yine de felaket senaryoları için erken olduğu da belirtiliyor.




 Google Play
Google Play App Store
App Store







 14:18
14:18
 İLGİLİ HABERLER
İLGİLİ HABERLER

