7 yaşındaki çocuğun bile çözebileceği soruda ChatGPT çuvalladı
OpenAI'ın en gelişmiş yapay zeka modellerinden biri olarak duyurulan ChatGPT-5.2 sürümü, 7 yaşındaki bir çocuğun bile rahatlıkla çözebileceği bir soruya yanlış cevap verdi.
Yapay zeka uygulamaları, günümüzde akla gelebilecek neredeyse her görevin altından kalkabiliyor. Ödevinizi hazırlamaktan karmaşık raporlar derlemeye, Spotify'da sizin için müzik listeleri oluşturmaktan sevdiğiniz türde bir şarkıyı tek promptla oluşturmaya kadar pek çok alanda kullanıcılara hizmet veriyor.
Ancak tüm yeteneklerine ve kapasitesine rağmen şaşırtıcı bir şekilde bazı temel görevlerde yetersiz kalıyor.
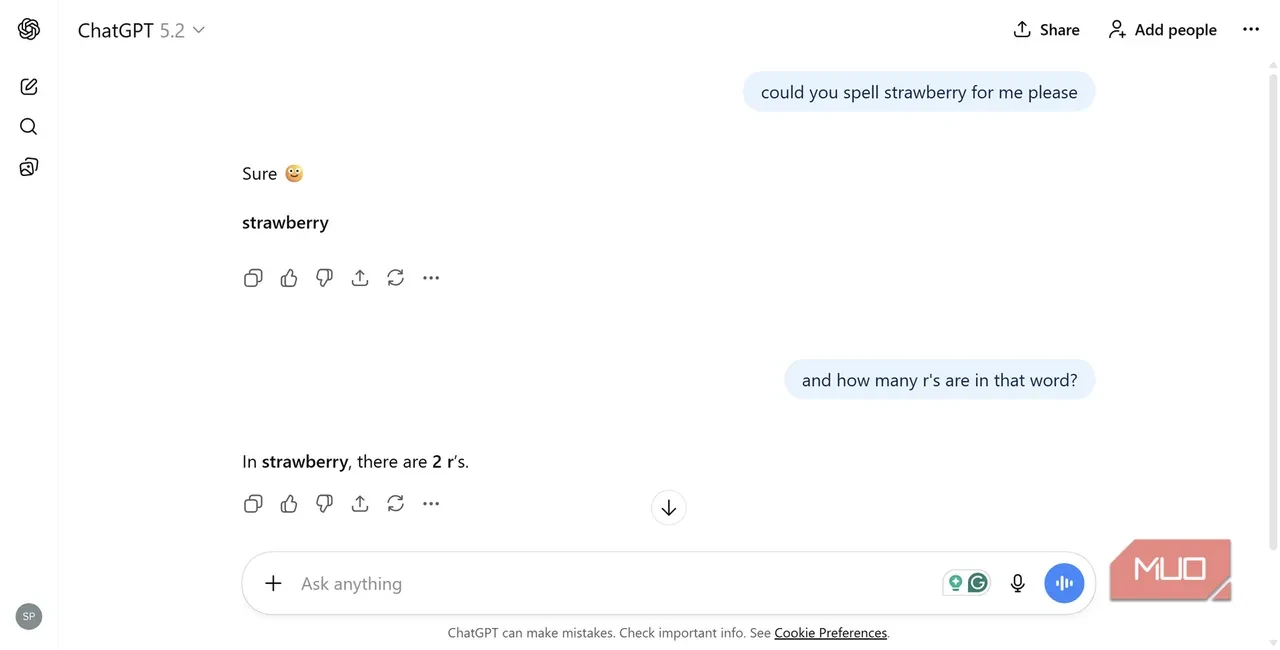
OpenAI tarafından geliştirilen ChatGPT'nin, İngilizce "çilek" anlamına gelen "strawberry" kelimesinde kaç tane "r" harfi olduğunu bulmakta zorlanması geçtiğimiz aylarda alay konusu olmuştu. ChatGPT'nin son yayınlanan GPT-5.2 güncellemesinde de sorunun hâlâ devam ettiği ortaya çıktı.
GPT 5.2 BİLE DOĞRU CEVABI VEREMEDİ
Aralık 2025'te kullanıma sunulan GPT 5.2 modeliyle birlikte, strawberry bilmecesinin çözülüp çözülmediği merak konusuydu. Normal şartlarda cevabın "üç" olduğu son derece açıkken, ChatGPT ise tabiri caizse gözünü bile kırpmadan yanlış bir cevap vererek "iki" dedi.
SORUNUN KAYNAĞI: TOKENİZASYON SİSTEMİ
Makeuseof.com'un haberine göre, yaşanan problemin temelinde ise yapay zeka modellerinin tasarımındaki "tokenizasyon" (girdi/çıktı ayrıştırma) mantığı yatıyor.
Kullanıcılar "strawberry" yazdığında, yapay zeka metni harf harf (S-T-R-A-W-B-E-R-R-Y) algılamıyor. Bunun yerine metni "token" adı verilen parçalara bölüyor. OpenAI Tokenizer aracıyla incelendiğinde, kelime "st", "raw" ve "berry" şeklinde üç farklı parçaya ayrılıyor.
Sistem, içinde "r" harfi geçen tokenları saymaya çalıştığında, "berry" ifadesini tek bir bütün olarak algıladığı için içindeki çift "r" harfini ayırt edemiyor ve değeri sıkıştırarak daha düşük bir sayı veriyor.
Benzer bir durum, ChatGPT'nin yine iki "r" harfi olduğunu iddia ettiği "raspberry" (ahududu) kelimesinde de yaşanıyor. Ancak model, "Mississippi" kelimesindeki harfleri doğru sayabiliyor veya "lollipop" kelimesini hatasız bir şekilde tersten yazabiliyor.




 Google Play
Google Play App Store
App Store







 11:26
11:26
 İLGİLİ HABERLER
İLGİLİ HABERLER
